A2DP Sink and Source on STM32 F4 Discovery Board
After a small detour handling Cross-Platform Console Input, we’re back and got audio streaming via A2DP to work in both directions on the STM32 F4 Discovery board.
Given the hardware options on the board, we’d like to play stereo music via the built-in Cirrus 43L22 Audio Codec and stream some music to a headset / loudspeaker, ignoring the microphone on the Discovery board.
Audio Playback with the Cirrus 43L22 Audio Codec
As the audio codec was already on the dev kit, we expected playing a simple sound like a sine wave to be a straightforward task, using Makefiles and the GNU ARM Embedded Toolchain.
We started with the excellent tutorial on configuring the STM32 F4 Discovery for audio. It looked quite promising since it did consist of only two source files. However, it is using the previous generation of the STM32 F4 Hardware Abstraction Library, and while the functionality is pretty similar, the APIs have changed a lot.
STM’s firmware v1.1 for the F4 Discovery board has an audio record and playback example, unfortunately, with project files only for commercial compilers (IAR, MDK, TrueStudio). In addition, it also uses the older HAL.
Then, we took a deeper look at the STM32CubeF4 SDK. To our surprise, it contained example code to configure the audio codec using the current STM32F4 HAL, of course, only for commercial IDEs as well. We slowly extracted the files related to audio codec configuration and actually succeeded to play a sine wave over the headphone output. Hooray! You can check it out at port/stm32-f4discovery-cc256x/src/bsp in the BTstack source tree.
BTstack Audio HAL
To allow to use different audio codecs in future BTstack ports, we’ve created a minimal audio playback HAL with an asynchronous interface, usable for event-driven systems.
/**
* @brief Setup audio codec for specified sample rate
* @param Sample rate
*/
void hal_audio_dma_init(uint32_t sample_rate);
/**
* @brief Set callback to call when audio was sent
* @param handler
*/
void hal_audio_dma_set_audio_played(void (*handler)(void));
/**
* @brief Play audio * @param audio_data
* @param audio_len in bytes
*/
void hal_audio_dma_play(const uint8_t * audio_data, uint16_t audio_len);
/**
* @brief Close audio codec
*/
void hal_audio_dma_close(void);
Asides from init/close, it provides a function to play audio samples and a callback when the playback is done.
HxCMOD Player
While playing a 441 Hz sine at a sample rate of 44100 Hz is terrific the very first time, it gets quickly a bit boring. By the way, we’ve used 441 Hz instead of A4 = 440 Hz as you’ll neatly end up with 100 samples for a complete waveform.
In the STM audio examples, a snippet of a wav file is used. But even with 1 MB of data stored in Flash, at 16 bit (/2), stereo (/2), music at 44100 Hz (/44100) only allows for 5 seconds playback – it’s 176 kB/s if you do the maths.
Other dev kits are able to play a longer wav file from an SD card, but then an SD card, an SD card driver and a file system are required as well, not making it very portable.
Remembering the 90’s – the demoscene, Soundtrackers, and MOD-Players – we found the HxCMOD player by Jean-François DEL NERO (Jeff) / HxC2001. It is a single C file without any dependencies. Best of all, it already came with a selection of songs (a.k.a. MOD files) that could be listened to via a JavaScript version of the MOD player.
Combining the HxCMOD player with our new audio playback HAL was a simple task.
#define NUM_SAMPLES 100
static uint16_t audio_samples1[NUM_SAMPLES*2];
static uint16_t audio_samples2[NUM_SAMPLES*2];
static volatile int active_buffer;
void audio_transfer_complete(void){
if (active_buffer){
hal_audio_dma_play((uint8_t*) &audio_samples1[0], sizeof(audio_samples1));
active_buffer = 0;
} else {
hal_audio_dma_play((uint8_t*)&audio_samples2[0], sizeof(audio_samples2));
active_buffer = 1;
}
}
void mod_player(void){
// init Audio HAL
hal_audio_dma_init(44100);
hal_audio_dma_set_audio_played(&audio_transfer_complete);
// init hxcmod engine
modcontext mod_context;
hxcmod_init(&mod_context);
hxcmod_setcfg(&mod_context, 44100, 16, 1, 1, 1);
hxcmod_load(&mod_context, (void *) &mod_data, mod_len);
// fill first buffer
hxcmod_fillbuffer(&mod_context, (unsigned short *) &audio_samples1[0], NUM_SAMPLES, NULL);
// play first buffer
hal_audio_dma_play((uint8_t*) &audio_samples1[0], sizeof(audio_samples1));
while (1){
// fill second buffer
hxcmod_fillbuffer(&mod_context, (unsigned short *) &audio_samples2[0], NUM_SAMPLES, NULL);
// wait for playback done of first buffer
while (active_buffer == 0){
__asm__("wfe");
}
// fill first buffer
hxcmod_fillbuffer(&mod_context, (unsigned short *) &audio_samples1[0], NUM_SAMPLES, NULL);
// wait for playback done of second buffer
while (active_buffer == 1){
__asm__("wfe");
}
}
}
We’ve used two audio buffers: while one buffer is played, the HxCMOD player fills the other buffer with new samples. When the playback is completed, the buffers are swapped and we start over. Here is the complete code for our modplayer based on HxCMOD.
For further experiments, we picked “Nao Deceased by Disease”, a song with only 7600 bytes that plays for a full minute.
After we’re able to play back audio, it’s time to finally play audio received via Bluetooth.
A2DP Audio Sink – Receiving Audio
For sending and receiving high quality audio, the Bluetooth A2DP (Advanced Audio Distribution Profile) profile is used, which sends the audio data over the AVDTP (Audio/Video Distribution Transport Protocol) protocol. After an audio stream has been setup, it mainly sends encoded audio frames as L2CAP packets. The SBC (Sub-band codec) audio codec is mandatory and does not require a license for use with Bluetooth. The SBC codec is also used for for Wide-Band Speech in the HFP profile, so the SBC encoder/decoder are ready in BTstack. Other codecs like mp3, aptX, or AAC can be implemented by device manufacturers as well.
In HFP, SBC frames are sent via a synchronous connection at a fixed rate. In contrast to this, A2DP sends data over ACL, which has a higher throughput, but does not give any guarantees about e.g. jitter.
If we would start playing the first packet and then the second packet has a small delay, we would get a small audible pause/click sounds. To avoid this, we decided to collect a few SBC frames in a ring buffer and allow to configure the amount of received SBC frames before we start playback.
For the playback, we’ve used the double buffering approach from before: play one buffer while using another one to decode the next SBC frame. For this, we process the received AVDTP packets and store the SBC frames individually in the ring buffer.
This wasn’t bad start: after connecting, the music from an iPhone played correct for a few seconds, but then, it suddenly stopped because we ran out of audio data. We took the chance and updated the code to resume playback after enough SBC frames have been cached again.
Playing around with the amount of frames buffered before playback starts, it became clear that there’s a proportional relation between the amount of buffering and the time until the audio got paused. This indicates that we were using (playing) the data faster than we receive it. A quick back-of-the-envelop calculation showed that we’re off, but only by a few percent. Too bad for playback, but nothing fundamentally wrong, like, e.g. a different playback sample rate.
Now, it was time to check at what rate the audio is actually streamed over the I2S bus. I2S is a synchronous serial bus. In a addition to a bit clock, there’s also a Word Select line, that is low for the first channel, and high for the second. This makes for an easy way to verify the output sample rate.
We looked at the I2S lines with Saleae Logic tool and its I2S protocol decoder.

|
Taking a closer look:
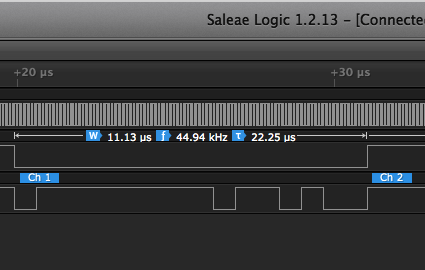
|
According to Logic, the audio frames are streamed at 45000 Hz – instead of the expected 44100 Hz. Well, that’s an error of 2%, and certainly too far off.
Diving deep into the datasheet, especially this table:
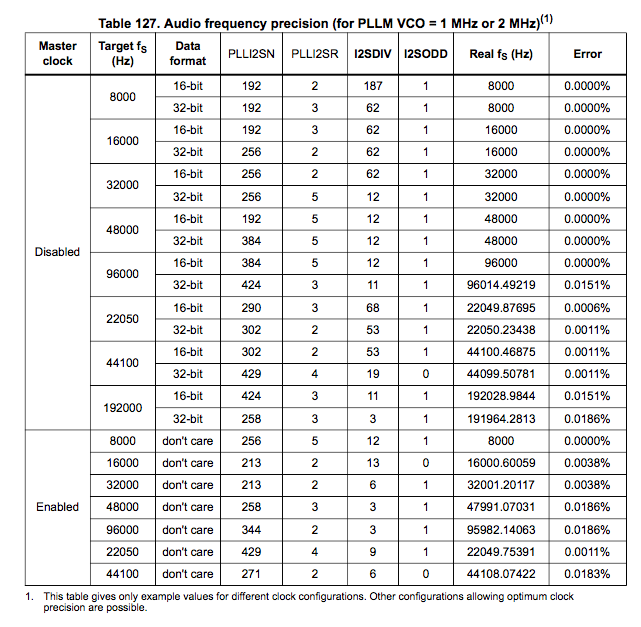
|
we learn two things: 1. With Master clock enabled – which is necessary for the audio codec as far as we know – it’s not possible to achieve a clock error of 0% for 44100 Hz. The best we should get is an error of 0.0183%. 2. It certainly shouldn’t be off by 2% either.
Configuring the I2S peripheral optimally requires a deeper understanding of the clock system, which we lacked. Instead, we took an easier approach and tried to find the code that does the configuration of the various registers (PLLI2SN, PLLI2SR, I2SDIV) based on the requested sample rate.
In stm32f4_discovery_audio.c, we first found this:
/* These PLL parameters are valid when the f(VCO clock) = 1Mhz */
const uint32_t I2SFreq[8] = {8000, 11025, 16000, 22050, 32000, 44100, 48000, 96000};
const uint32_t I2SPLLN[8] = {256, 429, 213, 429, 426, 271, 258, 344};
const uint32_t I2SPLLR[8] = {5, 4, 4, 4, 4, 6, 3, 1};
The values in the table look similar to the values suggested in the data sheet. That’s a good sign!
Then, we found the code that uses theses tables in BSP_AUDIO_OUT_ClockConfig()
uint8_t index = 0, freqindex = 0xFF;
for(index = 0; index < 8; index++) {
if(I2SFreq[index] == AudioFreq) {
freqindex = index;
}
}
First, it looks up the requested sample rate in the I2SFreq table and stores the index in freqindex, if found. Then after initializing the peripheral clock, the freqindex is used again.
/* Enable PLLI2S clock */
RCC_PeriphCLKInitTypeDef rccclkinit;
HAL_RCCEx_GetPeriphCLKConfig(&rccclkinit);
/* PLLI2S_VCO Input = HSE_VALUE/PLL_M = 1 Mhz */
if ((freqindex & 0x7) == 0)
{
rccclkinit.PeriphClockSelection = RCC_PERIPHCLK_I2S;
rccclkinit.PLLI2S.PLLI2SN = I2SPLLN[freqindex];
rccclkinit.PLLI2S.PLLI2SR = I2SPLLR[freqindex];
HAL_RCCEx_PeriphCLKConfig(&rccclkinit);
}
else
{
rccclkinit.PeriphClockSelection = RCC_PERIPHCLK_I2S;
rccclkinit.PLLI2S.PLLI2SN = 258;
rccclkinit.PLLI2S.PLLI2SR = 3;
HAL_RCCEx_PeriphCLKConfig(&rccclkinit);
}
Something’s wrong here. Given that the table only has 8 entries, the first conditional
if ((freqindex & 0x07) == 0)
only becomes true for freqindex == 0 – the first entry for 8000 Hz. For all other frequencies the ‘else’ path is used, which effectively uses the settings for 48000 Hz.
The ‘else’ path clearly was intended to pick some values in case the requested sample rate was not found in the table. However, it should use the values from the table, if it is found.
We went ahead and change the conditional to check if we got a match before:
if (freqindex != 0xFF)
With this fix, we got a better configuration.

|
That’s 44300 Hz, which is still off by 0.4% but much better than before. Playing audio works much longer, but it is still not perfect.
Given that we cannot configure 44100 Hz exactly, and that we might run into a case where the Bluetooth audio source is slightly off too, we decided that the I2S configuration is good enough for us now. However, we traded one problem for another: how to adjust/synchronize playback dynamically to the sender?
The general problem of synchronizing an audio source with an audio sink has been identified a long time ago. Solutions to deal with it often differ depending on the actual context: is audio played over a local network? Is there a way to provide feedback? What’s the maximal jitter? etc.
In A2DP, there’s no feedback loop, so all we can do is try to make the best of what we get. For higher quality audio, we receive SBC frames of 128 samples (left + right). If we just drop a single sample, or add one (e.g. by duplicating the last one), we can modify the length of the frame by almost 1% without audible artifacts.
With the assumption that computer clocks should not be off by a full percent, we tried to create a basic audio synchronization algorithm that adds or removes a single sample per SBC frame.
Now, when should a sample be added or dropped? If we would be able to perfectly measure the sample rate of the incoming audio data as well as the sample rate of the I2S output, we could calculate exactly how often we need to drop or duplicate a sample. Doing this measurements however isn’t an option as we cannot be even sure that our own clock is correct. Measuring our own I2S clock might be doable, but measuring the sample rate of the incoming data isn’t. We usually get 6-7 SBC frames in a single AVDTP packet every 20 ms with a high jitter. Given enough statistical data and efforts, it might be possible to measure the real sample rate of the source, but it’s not an easy approach.
Instead, we considered what data we have available on the audio stream. The most obvious piece of data is that the music stops when we run out of buffers. That’s only a single bit of information, but the number of SBC frames in the ring buffer is already a good indicator of how well we’re synchronized. Let’s see how the number of SBC frames changes over time. We print the time in ms and the number of SBC frames in the buffer each time an audio buffer is played.
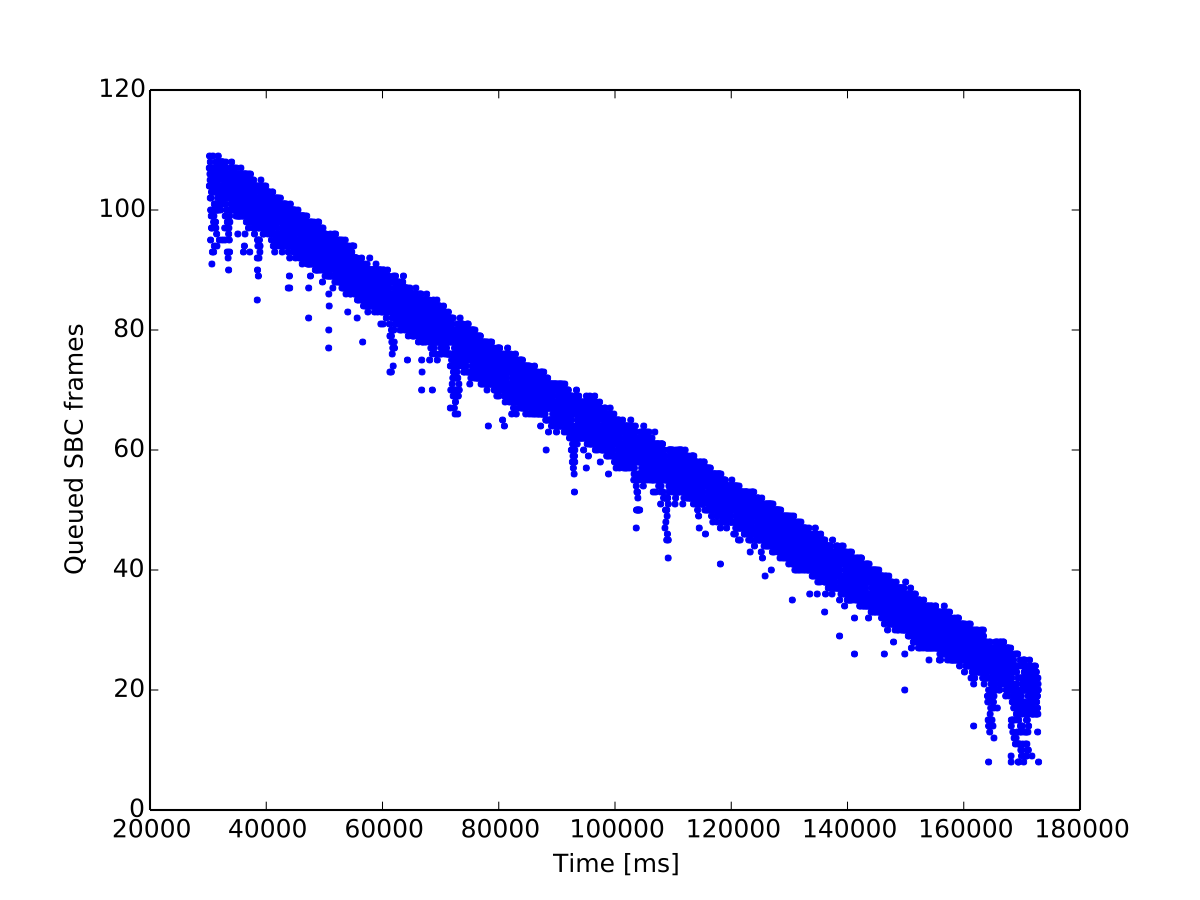
|
It’s clear from the plot that the audio is played faster than it’s received. The next observation is that the number of queued SBC frames probably would stay within some fixed range (more than x, less than y) if the audio would be in sync. This range directly hints at a basic algorithm: check the number of queued frames. If it’s above the high threshold, drop a sample from the next frame. If it’s below the low threshold, duplicate a sample in the next frame.
That’s nice, but when should this test be performed?
When a new AVDTP media packet is received, its SBC frames are stored in the ring buffer. The playback part continuously decodes SBC frames from the ring buffer and sends it over I2S without any jitter.
The playback part decreases the number of queued frames at a constant rate. Doing the check after packet reception provides an efficient way to constantly check the buffer with minimal logic.
Our code to correct audio drift actually becomes as simple as this:
#define OPTIMAL_FRAMES_MIN 30
#define OPTIMAL_FRAMES_MAX 40
// decide on audio sync drift based on number of sbc frames in queue
int sbc_frames_in_buffer = btstack_ring_buffer_bytes_available(&ring_buffer) / sbc_frame_size;
if (sbc_frames_in_buffer < OPTIMAL_FRAMES_MIN){
sbc_samples_fix = 1; // duplicate last sample
} else if (sbc_frames_in_buffer <= OPTIMAL_FRAMES_MAX){
sbc_samples_fix = 0; // nothing to do
} else {
sbc_samples_fix = -1; // drop last sample
}
The adding/removing of a sample then happens in the callback of the SBC decoder – as we can only remove/add PCM samples:
uint8_t * write_data = start_of_buffer(write_buffer);
uint16_t len = num_samples*num_channels*2;
memcpy(write_data, data, len);
audio_samples_len[write_buffer] = len;
// add/drop audio frame to fix drift
if (sbc_samples_fix > 0){
memcpy(write_data + len, write_data + len - 4, 4);
audio_samples_len[write_buffer] += 4;
}
if (sbc_samples_fix < 0){
audio_samples_len[write_buffer] -= 4;
}
In the end, this keeps adding samples or dropping samples until it gets back into the desired range without complex logic or audible artifacts.
As a result, music playback works well, and also deals with the 0.4% error of the I2S output sample rate. The complete code for the A2DP Sink is at example/a2dp_sink_demo.c
A2DP Audio Source – Sending Audio
While the F4 Discovery comes with a built-in microphone, we did not try to use it for two reasons: first, it has a peculiar interface that requires to link against a binary library provided by STM, and second, it’s not much fun to speak into a microphone to hear oneself in a Bluetooth speaker (-> feedback) or a headset. Instead, we’d rather play a MOD files via Bluetooth :).
After dealing with audio drift before, we’re now on the sending side and the best we can do is to generate audio at the nominal rate and to send it as constant as possible. Using the MOD player or a stored audio file, we can generate audio samples as fast as needed without any problems.
So, now we only need to find a way to send the audio at the configured rate. As audio needs to be sent periodically, we could use a timer in BTstack to get a periodic callback to send a packet. Timers in BTstack don’t provide much guarantees, the only guarantee is that they won’t fire before the given timeout and the the errors will accumulate with every timer expiration.
However, we can rely on the system to have a reasonably well working clock. Instead of trying to send packets based on the timer, we instead use the timer to periodically update the amount of audio frames that should have been sent at this point in time. Of course, this won’t be precise either, but it’s not accumulating errors on top of the clock accuracy.
First, we get time since the last update:
#define A2DP_SAMPLE_RATE 44100
uint32_t now = btstack_run_loop_get_time_ms();
update_period_ms = now - time_audio_data_sent;
Then, we calculate the number of samples and also accumulate fractional samples for this period:
uint32_t num_samples = (update_period_ms * A2DP_SAMPLE_RATE) / 1000;
acc_num_missed_samples += (update_period_ms * A2DP_SAMPLE_RATE) % 1000;
while (acc_num_missed_samples >= 1000){
num_samples++;
acc_num_missed_samples -= 1000;
}
time_audio_data_sent = now;
We can now update the number of samples that should have been sent by now:
samples_ready += num_samples;
If there are enough samples for an SBC frame, it gets encoded and added to the outgoing buffer. Finally, if the outgoing buffer has reached the maximal number of SBC frames, it is sent.
The complete code for A2DP Source is in example/a2dp_source.c.